
概率编程中的概率是指概率推理,特指贝叶斯方法里的概率及其求解;编程是指通过计算机编程语言(如Python)去实现建模和求解。其中关键是变分推断(Variational inference)技术。PyMC3是Python中实现概率编程的模块,它利用了新一代的MCMC抽样算法(如NUTS),因而计算速度快,使得概率编程容易实现。本文举了多个例子,其中线性回归的例子中详细介绍了pymc3的用法。
1.Windows/Python3.5安装pymc3和theano
step 1: pip3 install mingw # 利用pip或conda安装的mingw,而不是独立安装的mingw
把mingw模块的路径加入系统PATH:
D:\your-path\Anaconda3\MinGW\bin;
D:\your-path\Anaconda3\MinGW\x86_64-w64-mingw32\lib;
如果独立安装的mingw也在PATH中,需要删除。
step 2: pip3 install theano
打开Python测试代码:
import theano
theano.test()
step 3:pip3 install pymc3
python中测试:
import pymc3
2.拟合分布
问题:x=np.array([10, 20, 30, 29, 28, 30, 32, 16, 24, 26, 32, 40, 50, 31, 38, 35, 28])
假设x符合Poisson分布,求参数mu(即lambda)。这是一个最简单的模型,我们分别用最传统的极大似然法和贝叶斯方法去拟合Poisson分布。
极大似然法(MLE):
MLE只能给出一个点估计,无法对精确性进行评估
贝叶斯方法:
注意:开始我没加cores参数,运行时得到错误:ValueError: must use protocol 4 or greater to copy this object; since getnewargs_ex returned keyword arguments。google了才知晓(墙!),其原因是pymc3中默认启动多线程并行计算,需要pickle模块。而pickle适合Linux,在Windows环境下会有诸多问题(muliprocessing模块在windows下使用也有此问题)。最简单的解决方法是添加参数cores=1,即trace = sample(2000,start=start, step=step, cores=1),不耽误当前的练习,但这样会放弃多核计算的方便性。
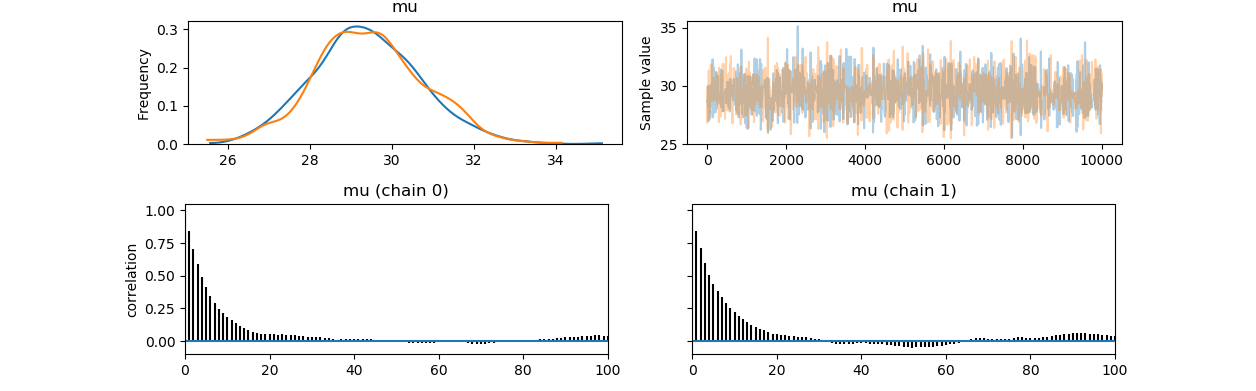
模型收敛的判断和结果提取:
3.分层拟合:分层方法已知时(独立模型思路)
例如上面拟合分布的例子,假设这批数据是已知两个群体的,其对应的分组为group=np.array([1,1,1,1,1,1,1,1,1,2,2,2,2,2,2,2,2])。
解决方案很简单,因为每个组的参数各自独立,所以通过一个循环即可解决。
4.分层拟合:分层方法已知时(融合模型思路)
上一个例子是独立建模的例子。但分层太多时,有些组个体数量很少,估计值有较大的不确定性(每个组分别通过hist函数画频数图、即可看出实际分布是否理论分布有差距)。此时,样本容量太小带来错误的结论。这时可以采取一种叫局部融合的思路。因为整体的数据量大,可以把每个组的后验预测分布联合起来,希望得到的分布和观测数据分布近似,顾名思义“融合”。加上任意的分布节点,对于概率编程/pymc3是很容易的。
独立模型是:(i为group)
yi~Poisson(μi)
μi=Uniform(0,100)
融合模型是:每个组的μi(称之为参数)受共同的超参数(又称融合参数)制约
yi~Poisson(μi)
μi=Gamma(μ,σ)
μ=Uniform(0,100)
σ=Uniform(0,60)
5.分层拟合:分层方法未知时(需求解分层的截断值)
这里涉及到了确定性随机变量(Deterministic random variable)的知识,因为这个截断值是random variable,但是deterministic(表面上看这两个词似乎矛盾,更多理解参考pymc3 tutorial)。这里模型混合了Stochastic random variable和Deterministic random variable,这大大增加了pymc3的应用范围。
问题:已知1851到1962年每年的矿难数,理论上服从Poisson分布。但从某一年开始矿难数下降,即Possion分布的参数改变了,求哪一年?
|
|
6.线性回归:
这里更详细的介绍pymc3的用法。这里的线性回归是只有Stochastic random variable的模型,即不涉及确定性随机变量(Deterministic random variable)(比如分层)
问题:
假设y~x1+x2+x3,求解系数(点值估计和标准差),预期x3系数为0
模型已经建好了,求解模型的方法有两种MAP法和抽样法。前者可以后者提供参数值的初猜,当然也可以不用。后者可以进行多轮模拟,前面的模拟(最后的取值,如trace[-1])为后面的模拟提供初猜。
Maximum a posteriori method:
MAP法使用了数值优化方法,计算速度快,但只能给出一个点估计(不能得到区间估计)。而且当选择取的分布不能代表模型时,其结果可能有错误。默认使用Broyden–Fletcher–Goldfarb–Shanno (BFGS)优化算法,还可以使用scipy中的。
Sampling method:
基于模拟的方法,即MCMC。具体实现MCMC的抽样方法有NUTS(连续变量), Metropolis(多分类变量), BinaryMetropolis(二分类变量), Slice, HamiltonianMC。
如果需要的话可以多轮
结果:
其中HPD是Highest Posterior Density,计算相当于频率派的可信区间。结果给出了95%的HPD区间: [hpd_2.5, hpd_97.5]
7.t检验:
两组x1和x2,判断均数是否有差别。产生随机数:
频率派的t检验方法:
贝叶斯方法:
x1和x2的均数、方差的估计值除了x1的均属其它还是很准确的。结果effect size的95%HPD为[-1.1884,-0.3523],effect_size等于0的概率小于0.05,即两组间有差别。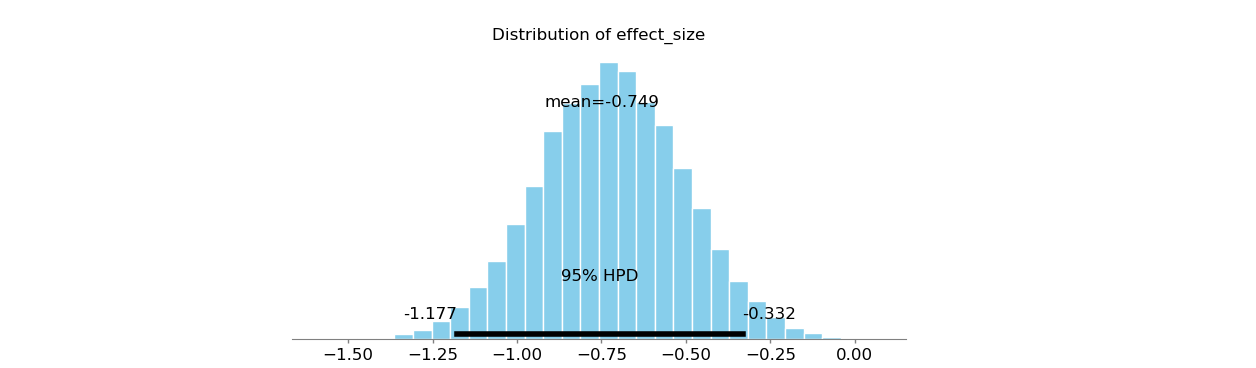
8.知识扩展:自定义确定性变量(Arbitrary deterministics):
pymc3调用了theano实现其变分推理,所以这儿也用theano自定义函数。
方法1:同前面矿难的例子
方法2:theano的as_op装饰器,见下:
9.知识扩展:pymc3预定义的回归模型
pymc3预定义了Linear regression model和Logistic regression model,可以不必自己构建model。用起来如同R语言的建模一样方便。
假设一般线性回归模型:y~x1+x2
假设Logistic回归模型:logit(y)~x1

