1.蛋白质聚类(Classification):

根据蛋白质的序列和结构相似性,把蛋白质进行聚类,分成不同类别。人们提出了家族(family)、结构域(domain)、序列特征(sequence feature)等概念用于蛋白质的聚类。
Family: 一组有相同进化起源的蛋白质。它们的序列、结构或功能相似。如著名的G蛋白偶联受体超家族(G-protein coupled receptor family),它的共同特点是:具有七个跨膜的结构域,并且与胞外信号结合后传递到胞内。从superfamily到family,再到subfamily,蛋白家族可以层层分类。
Domain: 蛋白质上的结构或功能单位,负责特定的功能或者蛋白质间相互作用。在不同的生物场景下,可有不同的功能。例如SH3结构域,由50个氨基酸构成,在蛋白质-蛋白质相互作用中有重要功能。一个蛋白质上可有多个结构域,甚至是相同的结构域。
Note: 基于Family和Domain的蛋白质聚类方法并不直观,而且不同的分类时有重叠。因为重叠,一组内的蛋白质可能有不同的功能。
Sequence feature: 是一组氨基酸序列,通常只有几个氨基酸。通过它可以确定蛋白质的特点,对把握蛋白质整体的功能更重要。如active site、binding site、PTM位点、repeat。
2.特征(Protein Signature)提取:
这是一种数学模型。其目的是,在蛋白质进行聚类前,需要对蛋白质进行序列比对(Alignment)、提取特征(Signature),以便预测Domain、Sequence feature等。通过比较多条序列共有的Signature,发现保守的序列,可以预测Domain等是否存在。
有多种方法可以提取Signature。常见的有四种signature:
Pattern: 许多重要的sequence feature,如酶上的结合位点、激活位点,包括几个蛋白质功能必需的氨基酸。Pattern可以很好地识别这些sequence feature。许多这种Pattern,被描述成正则表达式(regular expression),被称为motif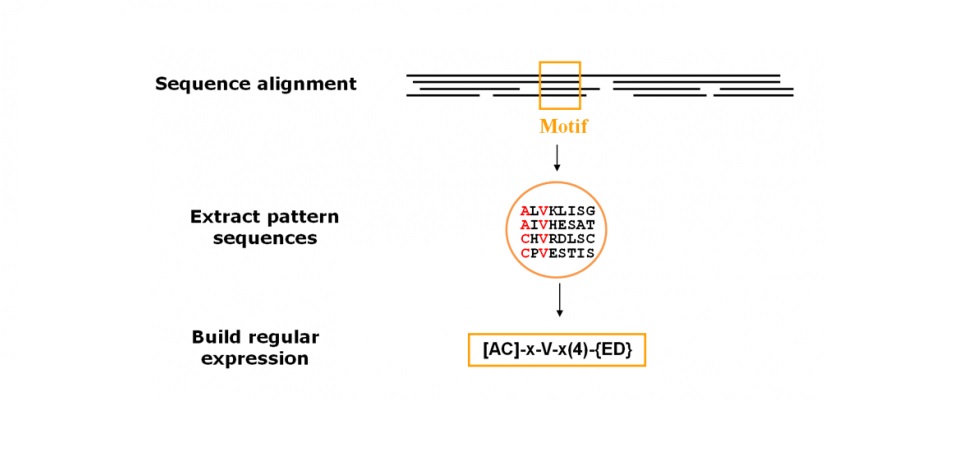
Fingerprint: 即指纹。单个motif可以很好地识别sequence feature。但大部分蛋白质分类往往有多个保守区。Fingerprint就是用来发现多个保守的motif。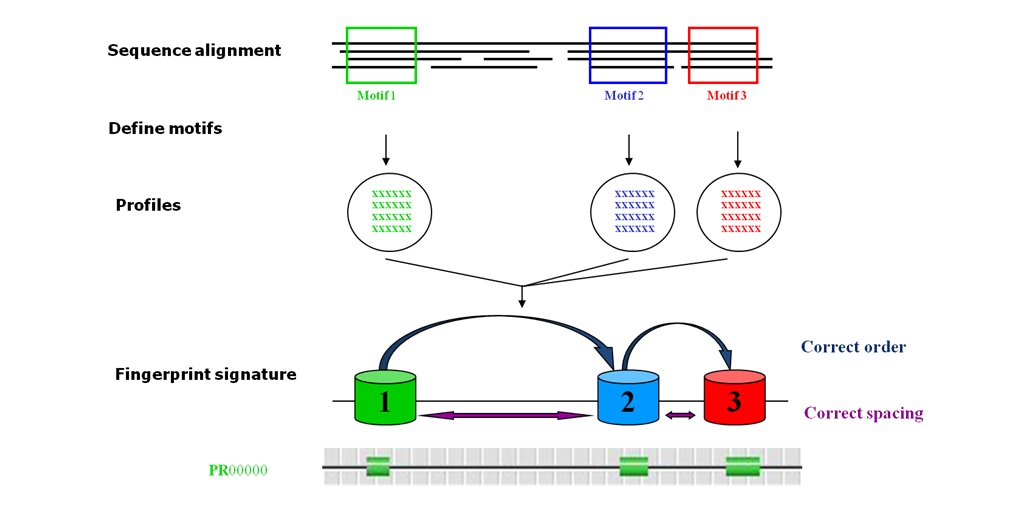
Profile: 用于描述Family和Domain。把多序列比对的结果转化成Position-specific scoring system(PSSM)。对每个位点上的不同氨基酸进行赋分。在这个过程中,通常会用BLOSUM等substitution matrix进行加权,考虑到进化距离的影响。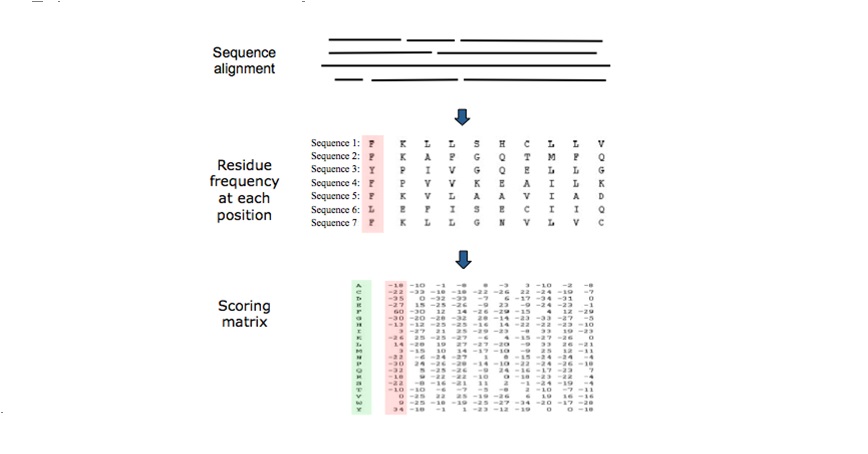
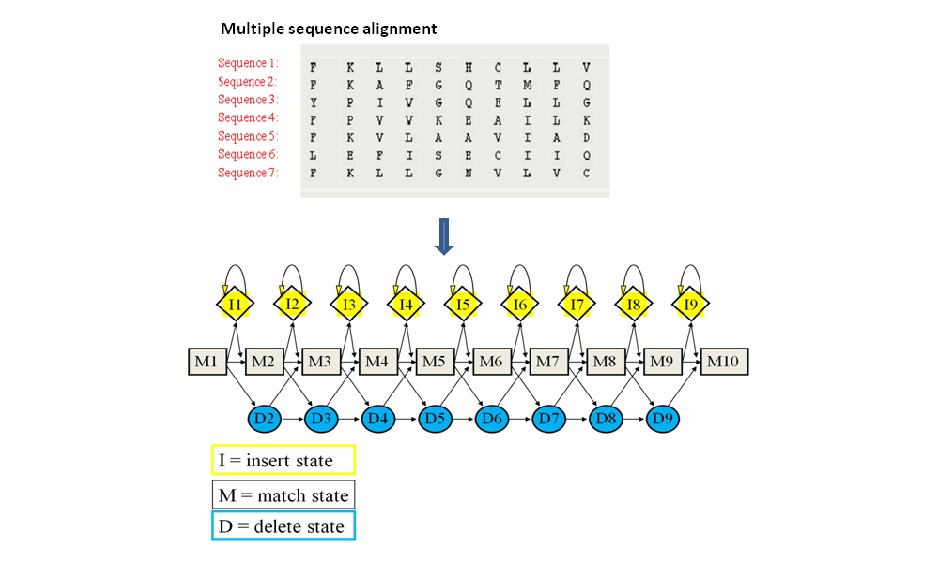
HMM : Hidden Markov models,一种概率转移矩阵 (Transition Probability) 。也是一种Position-specific scoring system。它充分考虑了氨基酸的插入和缺失,因此它可以对整个序列对比结果进行建模。非常适合寻找同源序列 (Homologous sequence)。